Determinants – The Answer to a Framework Manager Mystery
Editor’s Note: This blog was originally posted on February 1, 2010, and has been reviewed/updated on October 5, 2020. Quite some changes have been applied to Framework Manager tool over the past decade, we find that the tuning of determinants is still a valid approach to address issues of sharing dimensions among multi-facts, especially when two fact tables join the dimension tables at different level. For instance, sales goal vs actual sales, with sales goals typically are set at month/quarter level while actual sales are at day level. If it is just one or two measures involved in entire model, you may consider to create alias of dimension tables to join different fact tables at each level or construct custom summary in report itself. Have you implemented in other creative way? We would love to hear your feedback.
Determinants can play a crucial role in the overall performance and consistency of your Framework Manager model but remain one of the most confusing aspects of the application to most developers. This article will attempt to end the confusion.
Determinants are used so that a table of one grain (level of detail) behaves as if it were another actually stored at another grain. They are primarily used for dimension tables where fact tables join to dimension tables at more than one level in the dimension. (There are other cases where you could use them, but they are less common and fairly specific situations.)
The Situation
Let’s use the example of a date dimension table with day level grain. If all the fact tables join at the day level, the most detailed level, then you do not need determinants. But as many of us know from experience, this is not always the case. Fact table are often aggregated or stored at different levels of granularity from a number of reasons.
The Problem
The trouble arises when you wish to join to the dimension table at a level that is not the lowest level. Consider a monthly forecast fact table which is at the month level of detail (1 row per month). A join to the month_id (e.g. 2009-12) would return 28 to 31 records (depending on the month) from the date dimension, and throw off the calculations. Determinants solve this problem.
The SQL
Often when modeling, it’s useful to think about the SQL code you would like to generate. Without determinants, the incorrect SQL code would look something like this.
SELECT F.FORCAST_VALUE, D.MONTH_ID, D.MONTH_NAME FROM SALES_FORECAST F INNER JOIN DATE_DIM D ON F.MONTH_ID = D.MONTH_ID
This code will retrieve up to 31 records for each of the sales forecast records. Applying mathematical functions, for example Sum and Count, would produce an incorrect result. What you would like to generate is something along the following lines, which creates a single row per month, AND THEN join to the fact table.
SELECT F.FORCAST_VALUE, D1.MONTH_ID, D1.MONTH_NAME FROM SALES_FORECAST F INNER JOIN ( SELECT DISTINCT D.MONTH_ID, D.MONTH_NAME FROM DATE_DIM D ) AS D1 ON F.MONTH_ID = D1.MONTH_ID
As shown above, the trick is to understand which columns in the dimension table are related to the month_id, and therefore are unique along with the key value. This is exactly what determinants do for you.
Unraveling the Mystery in Framework Manager
Following Cognos best practices, determinants should be specified at the layer in the model in which the joins are specified.
Here we see a date dimension with 4 levels in the dimension, Year, Quarter, Month and day level.
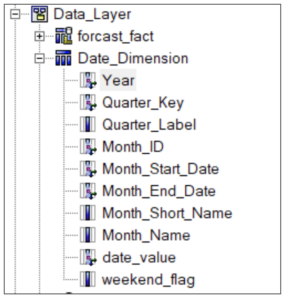
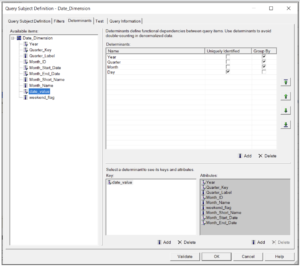
This means we can have up to 4 determinants defined in the query subject depending on the granularity of the fact tables present in your model. The first three levels, Year, Quarter, Month, should be set to “group-by” as they do not define a unique row within the table and Framework Manager needs to be made aware that the values will need to be “Grouped” to this level. In other words, the SQL needs to “group by” a column or columns in order to uniquely identify a row for that level of detail (such as Month or Year). The Day level (often called the leaf level) should be set to “Uniquely Identified”, as it does uniquely identify any row within the dimensional table. While there can be several levels of “group by” determinants, there is typically only one uniquely identified determinant, identified by the unique key of the table. The “uniquely identified” determinant by definition contains all the non-key columns as attributes, and is automatically set at table import time, if it can be determined.
The Key section identifies the column or columns which uniquely identify a level. Ideally, this is one column, but in some cases may actually need to include more than one column. For example, if your Year and Month values (1-12) are in separate columns. In short, the key is whatever columns are necessary to uniquely identify that level.
Using our aforementioned table, the setup would look like this:
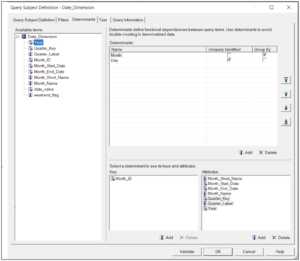
The Attributes section identifies all the other columns which are distinct at that level. For example, at a month_id (e.g. 2009-12) level , columns such as month name, month starting date, number of days in a month are all distinct at that level. And obviously items from a lower level, such as date or day-of-week, are not included at that level.
Technically, the order of the determinants does not imply levels in the dimension. However, columns used in a query are matched from the top down which can be very important to understanding the SQL that will be generated for your report. If your report uses Year, Quarter and Month, the query will group by the columns making up the Year-key, Quarter-key and Month-key. But if the report uses just Year and Month (and not the Quarter) then the group by will omit the Quarter-key.
How Many Levels Are Needed?
Do we need all 4 levels of determinants? Keep in mind that determinants are used to join to dimensions at levels higher than the leaf level of the dimension. In this case, we’re joining at the month level (via month_id). Unless there are additional joins at the year or quarter level, we do not strictly need to specify those determinants. Remember that year and quarter are uniquely defined by the month_id as well, and so should be included as attributes related to the month, as shown.
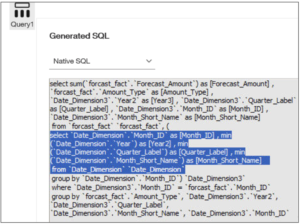
The Result
Following these simple steps the following SQL will be generated for your report. The highlighted section is generated by the determinant settings. Notice how it groups by the Month_ID, and uses the min function to guarantee uniqueness at that level. (No, it doesn’t trust you enough to simply do a SELECT DISTINCT.) The second level of group by is the normal report aggregation by report row. So the result is that the join is done correctly, which each monthly fact record joined to 1 dimensional record at the appropriate level, to produce the correct values in the report.