The Why, What, Who, and How of Successful Hadoop Deployment

Today, our world is filled with data. It has quietly become part of our daily life, and we’ve changed our routines to accommodate it. Beyond the impact it’s had on us, data itself has dramatically changed over the past two decades due to continual advances in internet and storage technology. Almost everything we interact with now is digital: web browsers, smart phones, tablets, social media accounts, and much more.
So where does all the data that supports our technological endeavors go? Because of all the different forms it can take based on where it comes from and how it’s handled, saved data in any environment is usually stored in a giant mix of structured, unstructured, and semi-structured formats. For this reason, one of the main concerns taking center stage in the data science world is the explosion of new data generated from all types of sources.
Enterprises across the globe acknowledge the fact that the vast amount of digital data they collect has the potential to provide invaluable business insights. The problem, however, is that this data is just too diverse and dense to be easily gathered and analyzed. In fact, few companies have actually been able to extract 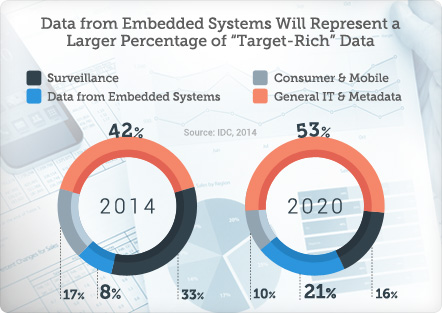 meaningful intelligence from all of their data and maximize its full potential. One recent EMC report
meaningful intelligence from all of their data and maximize its full potential. One recent EMC report
estimated that only 0.5 percent of all data is being analyzed. Many organizations are simply trying to jump in on the action to analyze “big data” without a true strategy or understanding of what big data is. As of 2014, IT data and metadata make up the majority of the target rich information that organizations want to explore. This trend will continue to grow as big data projects expand and as metadata builds up, even branching out to include metadata on metadata .
Among big data analytics implementations, Hadoop stands out as one of the top selections. In this article, we’ll discuss why this is the case and provide you with all the key points that beginning big data analysts need to consider when starting their journey with this powerful and innovative technology.
Why Hadoop?
There are a number of reasons why Hadoop is an attractive choice for big data management. Some of its major benefits are as follows:
- Hadoop offers distributed computing and computational capabilities on commodity hardware.
- It is scaled to meet the exponential increase in data generated by both traditional physical media and digital technologies.
- It handles large volumes of structured and unstructured data much more efficiently than a traditional enterprise data warehouse.
- It has the flexibility to integrate data from different sources, systems and file types.
- Its data processing speed is faster than traditional ETL processing thanks to its parallel processing capabilities, which can perform jobs 10 times faster than those running on a single thread server or on the mainframe.
These advantages, along with Apache’s strong reputation and high-profile implementations by internet giants such as Facebook, Google, Yahoo, eBay, and numerous Fortune 100 companies, are making Hadoop a go-to technology for handling massive loads of information in multiple formats.
Hadoop Architecture
Before starting a Hadoop implementation, you need a solid understanding of how its architecture design diverges from more standard structures. To highlight this, let’s first take a look at the comparison of traditional enterprise data warehouse (EDW) architecture and big data architecture shown below:
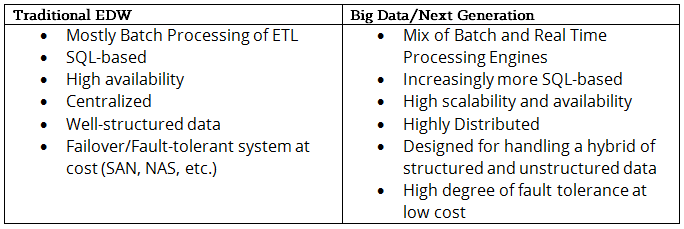
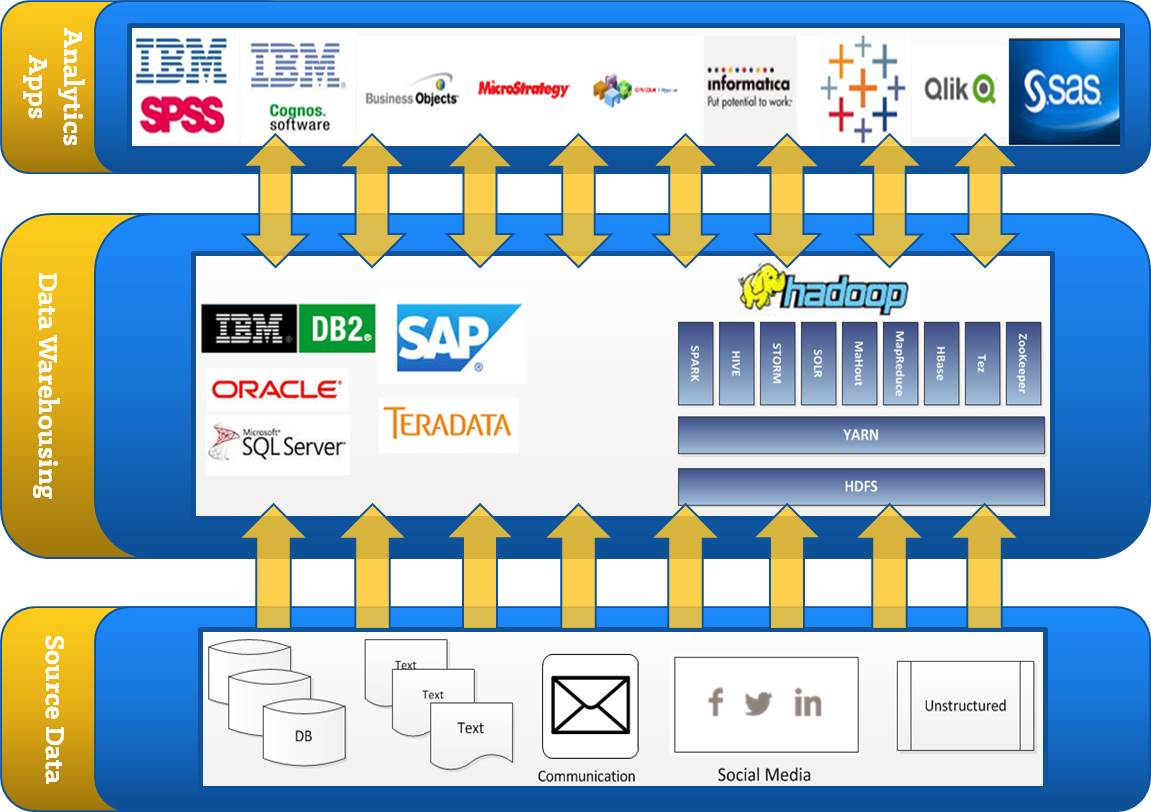
Understanding the high-level view of the architecture shown above provides a good background for understanding big data and how it complements existing BI, analytics, EDW, and other related systems. This architecture is certainly not a fixed template for every implementation. Each component may have several alternatives depending on actual business requirements and workload. The number one design rule is to be flexible and expandable.
Hadoop Implementation Considerations
Like any other technology, there is no one-size-fits-all approach for a Hadoop analytics implementation. It is common to encounter a few roadblocks when implementing your big data strategy. Understanding, researching, and planning well are key factors that will lead you to successful execution.
Here are some important areas to consider:
Architecture
As Hadoop is a fairly new technology, it can be hard to get started and difficult to maintain due to lack of industry knowledge and trained professionals. Bringing in expert consultants and engineers is essential to delivering a good Hadoop architecture based on an organization’s specific requirements and needs. Deploying and managing a Hadoop cluster at scale is not trivial, and the hardware it runs atop should be optimally tuned for performance and reliability. If you don’t already have staff with experience managing and deploying Hadoop in your data center, we strongly advise looking at Hadoop as a service or some other form of management and cloud hosting of your cluster.
Data Integration and Transformation
Feeding data into Hadoop only solves a very small part of the wider big data problem. To get insights from source data, you need the ability to process and analyze the data efficiently. Dedicated data engineers (those with a software engineering background not always found in your existing staff of ETL developers) will help you to build data processing pipelines and deploy predictive models that your data science team has developed. This new role is essential for building the right analytics solutions to capitalize on your Hadoop infrastructure and integrate it with business process to drive outcomes.
Security Management
Starting early with security is vital. Determine your data privacy protection strategy during the planning phase, preferably before moving any data into Hadoop. Identify data elements that are sensitive and consider your company’s privacy policies, pertinent industry regulations, and government regulations. Often times early-phase Hadoop projects or use cases are more experimental and the need for security and governance is not apparent or necessary, but if your initiative proves viable you will want to have a referenceable plan in place in advance.
Designing for High Availability
One of the advantages of Hadoop is that it provides a very high degree of fault tolerance. Rather than relying on high-end hardware, the resiliency of Hadoop clusters comes from the software’s ability to detect and handle failures at the application layer. Replication of HDFS nodes provides important protection against unexpected downtime if part of the network or data storage system goes offline.
Coupling Data with Analytics
The true value of Hadoop and associated concepts like the “Data Lake” or “Data Reservoir” is the ability to do analytics over a variety of different data sources both internal and external that are both structured and unstructured. Your Hadoop environment is essentially a data scientist’s playground where experiments can be run quickly and iteratively without having to take on the cost and risk of loading a structured data warehouse to test a fleeting idea that may not live on past tomorrow. To do this successfully you’ll want to ensure skill sets are aligned to take advantage of this new resource – chances are if you are taking an iterative approach you’ll already know exactly why you’ve built your environment before you even start. You’ll need data scientists to help, and in order to empower your existing staff you’ll want to pay close attention to the rapidly improving support for SQL on Hadoop, which will open up access to all of your existing skill and tool sets.
Using an Agile and Iterative Approach
You will want to start your big data project with a specific use case, business outcome, and initial data set already identified (avoid the classic “if you build it, they will come” pitfall of Hadoop implementation). Over the course of a project, however, you will encounter unanticipated scenarios that give you a deeper understanding of what you need to successfully complete the project. Using agile and iterative implementation techniques will deliver quick solutions that adjust to the current situation instead of causing frustration every time you hit a big rock blocking you from your expected process. This strategy lets you start small but think big.
Conclusion
A well-managed Hadoop implementation results in incredible business outcomes and strategic value , even though its initial implementation can be daunting. Achieving ideal results from a Hadoop implementation begins with choosing the right hardware and software stacks for your situation. The amount of effort you put into planning for both Hadoop and the other infrastructure pieces surrounding it will pay off dramatically in terms of the performance and the total cost associated with the environment.
Sound too complicated? Have a use case in mind but don’t know where to get started? Want to know more or need help navigating the hype around Hadoop, Data Lakes and Big Data in general? Contact us today to learn more or start planning your Big Data project in a way that will show your organization real value and drive tangible business outcomes that affect the bottom line.
Reference:
EMC: http://www.emc.com/leadership/digital-universe/2014iview/images/rich-data-by-type.jpg


