Migrating from Oracle to Netezza

Many are looking to IBM Puredata System for Analytics (Netezza) but are unsure of the complexity of implementation. Is it a lift and shift? Is there redevelopment involved? The focus of this article is to describe the process for migrating from Oracle. At a high level this process is the same when migrating from other RDBMS but every RDBMS has its own nuances that should be taken into consideration.
Puredata Background
IBM Puredata System for Analytics (Netezza) is an integral part of the IBM Big Data platform and is often an important part of most big data solutions. It is a true Data Warehouse Appliance that integrates Server, Database, and Storage in Asymmetric Massively Parallel Processing (AMPP) Architecture. It is an out-of-box solution that offers processing speeds 10-100 times faster than traditional systems, requires minimal administration and tuning, and has the ability to easily scale up to Petabytes of user data. It comes with an embedded Analytics engine, which is an extensible and advanced analytics software platform that simplifies the development, deployment, and use of advanced analytics while delivering high performance and scalability.
It is important to note that Netezza is data model agnostic and the single most important factor that will impact performance is the data distribution across the various disks. For further details please refer to these earlier articles Design Best Practices and Guidelines and Importance of Data Distribution for Optimal Performance.
The Process for Migrating from Oracle to Netezza
(This process is the same when migrating from other RDBMS except certain database specific alterations)
1. DDL (Data Definition Language) Extraction from Oracle
Generate the detailed DDL for ALL the objects in the database to be migrated in delimited text file(s) using tools like TOAD, Oracle SQL Developer, or Oracle Java Developer (just to name a few) or using inbuilt Oracle packages.
2. Analyze the Objects and Related Code (DDL) in Oracle
It is important to understand the different objects to be migrated along with the associated DDL code. Objects like Stored Procedures, Sequences, user-defined functions, and any other DB objects written in PL/SQL will have to be reviewed and manually converted into Netezza-compatible SQL.
3. Delete Unnecessary Definitions
Delete information like logging, storage, index (if any), tablespaces, partitioning, etc. from the table creation definitions. If a Primary Key is defined in Oracle then Netezza will automatically distribute the data using Hash partitioning on this column else a distribution key should be defined accordingly.
As a best practice, define the foreign keys even though Netezza does not enforce them.
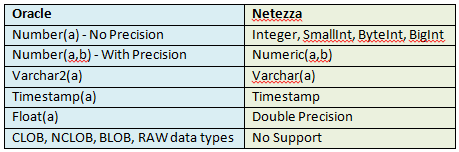
4. Change the Data Types
Some of the data types do not match directly between Oracle and Netezza and these will have to be changed accordingly.
As a best practice, always use the smallest matching data type in Netezza, as the scan speed in the Netezza warehouse is directly proportional to the data scanned.
5. Deploy the Modified DDL to Netezza
To deploy the table definitions, other DB objects, and constraints to Netezza, copy the DDL file(s) to the relevant directory on an external storage device or an NFS share (It is not recommended to use the host as a staging area) and execute the script(s) from the nzsql interface. (Netezza will throw warnings saying that it will not enforce the PK-FK relationships)
6. Data Extraction from Oracle
There are different ways to export the data when migrating from Oracle – directly using ETL tools like IBM InfoSphere Datastage or indirectly using different Oracle functions and stored procedures or 3rd party utilities. It is recommended to change the date data type while exporting to a Netezza-compatible format, as Oracle by default exports Date and Timestamp in different date formats.
As a best practice, create delimited files, one or more per table, based on data volumes with UTF-8 format without using BOM (Encoding) or the ANSI – Latin 1 (default) character set.
7. Data Loading into Netezza
Create a user and/or group and assign relevant permissions to connect and load data in the Netezza database. Data can be loaded directly using ETL tools or indirectly using nzload to load the flat file(s) created in the above step. Another approach would be to use UNIX named pipes to directly load the data into Netezza from Oracle (leverages External tables). nzload allows you to load data from the local host or from a remote client on supporting client platforms. Data can then be loaded to a table individually or to multiple tables in a single transaction.
As a best practice, before inserting the data make sure that you only load records that do not violate the foreign key constraints of the fact table. You can do this by first loading the data into a temporary table, then only loading data into the fact table that has corresponding key values in the dimension tables. You can verify this through inner joins. This is a very fast and efficient way to check key constraints during loads in Netezza.
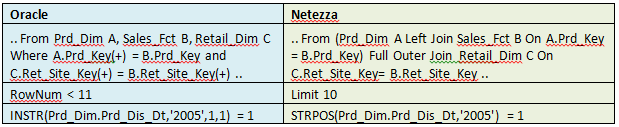
8. DML Migration from Oracle
Oracle complies with SQL-92 or SQL/2 ANSI/ISO standards like the Netezza appliance but also has a lot of added proprietary functions. It also allows the use of non-standard syntax, for example for JOIN expressions, and because of this these expressions need to be manually migrated as well.
9. Performance Optimization
Once the data is loaded it is important to analyze the distribution key(s) to ensure that the data is distributed evenly across all disks and to reduce the data skew. You can leverage the script called nz_best_practices as part of the Netezza support tools (/nz/support/bin) to perform a Health-Check on the database and help fix bad schema practices like bad distribution keys, statistics statuses, Data Type Issues, Inconsistent Data Types, and so on.
As a best practice, run Generate Statistics to have up-to-date statistics on all tables in the database after the migration.
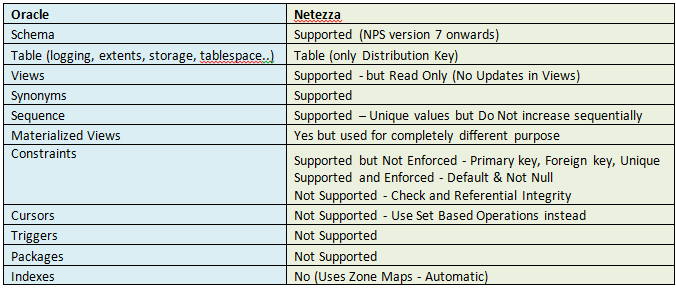
Database Object Mapping between Oracle and Netezza
Other Important Factors to Consider when Migrating from Oracle or Any Database to Netezza
- Identify all embedded SQL queries in the ETL mappings/jobs/scripts and convert these to Netezza-specific SQL.
- Move from a transaction-based ETL to a set-based ETL approach to leverage the power of Netezza.
- Identify and convert all embedded SQL in downstream reporting applications to corresponding Netezza SQL.
Leveraging its synergy with IBM products, the following solutions are available for use with IBM Netezza Analytics:
IBM BigInsights with Netezza
A core component of IBM’s platform for big data, IBM InfoSphere BigInsights is inspired by, and is compatible with, open source Hadoop and is used to store, manage, and gain insights from Internet-scale data at rest. When paired with IBM Netezza Analytics via a high-speed connection, massive volumes of distributed data and content, as well as ad-hoc analytics, can be processed quickly and efficiently to find predictive patterns and glean valuable insights.
IBM Cognos and IBM SPSS with Netezza
The combination of Cognos Business Intelligence and IBM SPSS Modeler with a Netezza enterprise data warehousing appliance ensures the fastest distribution of the best information to the entire business; accelerating decision-making for better business results. Netezza data warehouses are built for analytics queries, so they are the perfect fit for Cognos Business Intelligence and SPSS. The result is the fastest time to insight, which achieve actionable results faster.
Please feel free to contact us if you need additional information on some interesting Big Data use cases using Netezza & BigInsights or more information on any of the IBM Big Data platform tools like Netezza, BigInsights, Streams or Data Explorer.


