The Importance of Data Preparation for Business Analytics

In today’s “Big Data” era, a lot of data, in volume and variety, is being continuously generated across various channels within an enterprise and in the Cloud. To drive exploratory analysis and make accurate predictions, we need to connect, collate, and consume all of this data to make clean, consistent data easily and quickly available to analysts and data scientists.
As a result, Data Preparation (often called Data Wrangling) plays a significant role, especially in the context of Self-Service (Ad-Hoc) Analytics and AI/predictive modeling.
What Is Data Preparation?
Data preparation is a pre-processing step that involves cleansing, transforming, and consolidating data. In other words, it is a process that involves connecting to one or many different data sources, cleaning dirty data, reformatting or restructuring data, and finally merging this data to be consumed for analysis. More often than not, this is the most time consuming step of the entire analysis life cycle and the speed and efficiency of the data prep process directly impacts the time it takes to discover insights.
Why Is Data Preparation Important?
Self-Service Analytics: As businesses demand faster and more flexible access to data, self-service analytics plays a key part in enabling business users to quickly prepare their own data for exploratory analysis (Mode 2 as defined by Gartner) thereby accelerating the time-to-insight by allowing an organization to bypass the IT bottleneck (as projects can take months or years to deliver) and ultimately driving better business decision making. Data sources are prepared on the fly for analysis, thus eliminating the need for complex ETL processes for data discovery.
Predictive Modeling: According to a Forbes survey, data scientists spend almost 80% of their time on data preparation.
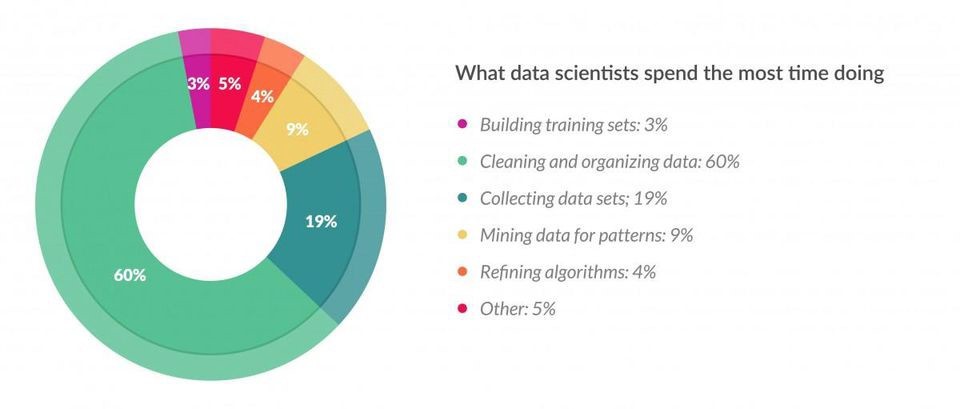
Most data scientists spend the majority of their time on collecting different types of data and then preparing that data to make feature (meaning fields/attributes) engineering decisions prior to actually building, testing, and training the model.
Feature Engineering is a process where features are changed or new ones are derived to improve the model performance in terms of accuracy. This is where the business domain expertise is needed and involves adding new data sources, applying business rules, and reshaping or restructuring the data to interpret it correctly. For example, if we want to predict retail sales for a specific time period – the holiday season for instance – it is important to understand the seasonal nature of the business and add a feature that identifies the shopping period, as this may be when the highest sales are expected.
What Does Data Preparation Entail?
Data Access: Since data is stored differently based on the type of data, different sets of tools are needed to connect to the respective data sources. For example, structured data is stored in relational databases and uses SQL to query the data, unstructured data stored in Hadoop would use Hive, Spark or Pig, data extracts for file formats like CSV, TXT, JSON, XML, etc., and for other formats tools like Python and R are used. In other words, to be able to connect to all different sources is a cumbersome and difficult task, especially for analysts and data scientists.
Data Profiling: Perform an analysis to check data quality and identify fields with no information value that could skew the model for predictive analysis. This might include contants, blanks, and duplicates and take an informed decision on how to address such issues or ignore such fields.
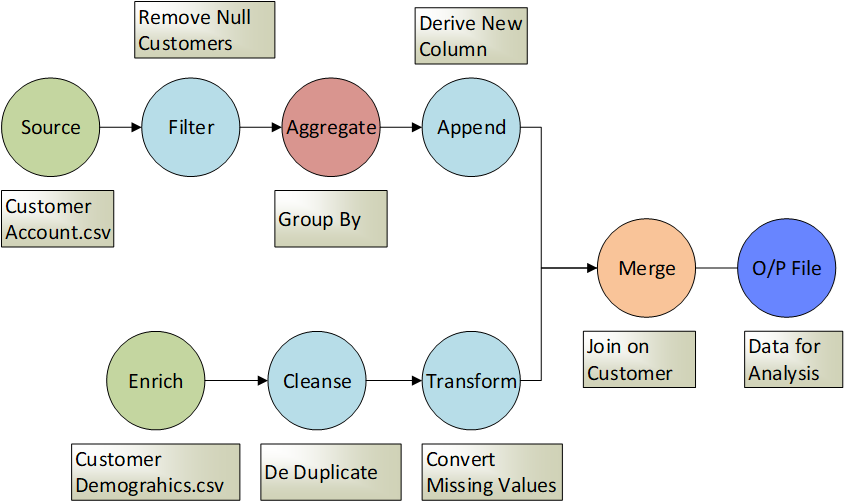
Cleaning up messy data involves tasks such as:
- Merging: Combine/enrich relevant data from different datasets into a new dataset
- Appending: Combine two smaller (but similar) datasets into a larger dataset
- Filtering: Rule-based narrowing of a larger dataset into a smaller dataset
- Deduping: Remove duplicates based on specific criteria as defined
- Cleansing: Edit or replace values, i.e. some records had “F” as gender while others had “Female”; alter to have “Female” for all records or set NULL values to a default value
- Transforming: Convert missing values or derive a new column from existing column(s)
- Aggregating: Roll up data to have summarized data for analysis
Sampling & Partitioning: This involves breaking down the entire dataset into a smaller set of sample data to reduce the size of the training data. These samples are then used for training, testing, and validating the model. It is important to ensure that the sample set includes data covering various scenarios to ensure the model is trained accordingly and not end up with a biased or inaccurate model.
What Tool(s) Do You Need?
There are many tools available in the market like Trifacta, Alteryx, Datawatch, Paxata, and others that offer features like visual profiling & transformations, build & schedule pipelines, data mashup & blending, and enable self-service discovery. Each one has their respective strengths and I recommend that you spend some time identifying the right one for your specific business needs.
Whichever tools you choose to use, the overall objective is the same:
- Help improve the efficiency and productivity of analysis
- Assist with agile development of new data pipelines
- Enable collaboration between lines of business, analysts, and IT
It is important to understand that data preparation tools are not intended to replace existing ETL/ELT processes, are not an enterprise solution, and offer minimal governance. Self-service analytics offers complete democratization of data management tasks in the hands of business users and thus poses a serious risk to data quality and data privacy. So unless data governance policies take these risks into consideration through clearly defined rules, procedures, and access controls, the intended gains from self-service analytics may not be achieved.

If you enjoyed this article and want to read more written by Nirav Valia, view his collection.
About Ironside
Ironside was founded in 1999 as an enterprise data and analytics solution provider and system integrator. Our clients hire us to acquire, enrich and measure their data so they can make smarter, better decisions about their business. No matter your industry or specific business challenges, Ironside has the experience, perspective and agility to help transform your analytic environment.

