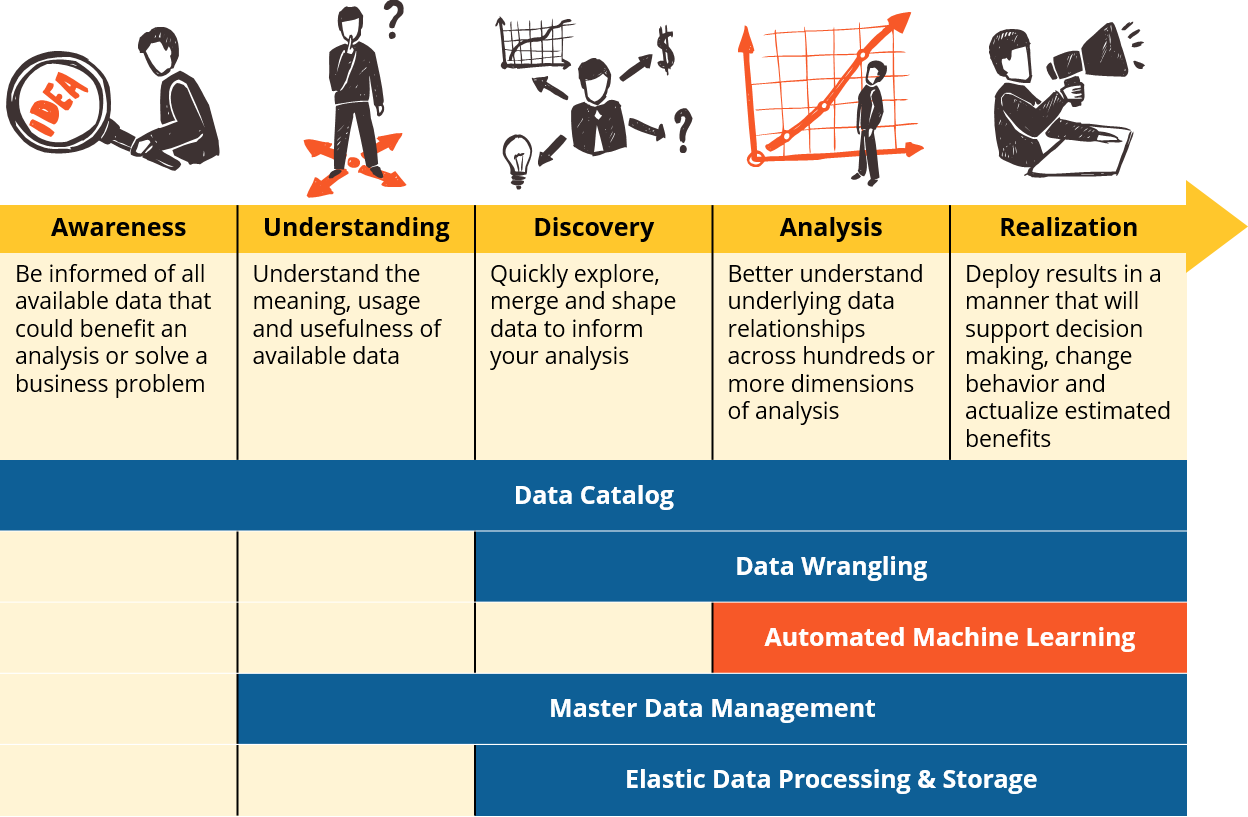
Five Essential Capabilities: Automated Machine Learning

This is part three in our five part series on the essential capabilities of the competitive data-driven enterprise.
Most business analysts will reach for their favorite data visualization tool when it comes time to perform driver and correlation analysis when in search of a cause. While this technology is essential for communicating with data, and excellent at identifying new opportunities (i.e. visualizing gaps or data non-relationships), it is limited in its ability to produce reliable, accurate and conclusive results. This is mostly due to our own human limitations when visually processing more than two dimensions of analysis at a time (e.g. revenue over time by product line).
By this point, most are probably aware that machine learning and associated methods of probabilistic analysis use powerful algorithms that can simultaneously analyze and weight hundreds or thousands of dimensions to better understand what is correlated, or driving a business outcome. You can also use this analysis to produce estimates or predictions that can then be deployed in an operational fashion to improve business processes in a variety of meaningful and measurable ways. The problem with machine learning to date is that it has been the complex realm of computational experts, statisticians and data scientists.
Most veteran data scientists who have had the experience of building and deploying machine learning models in a business environment would explain that this is a bit of a paradox, because one of the most important ingredients to effective problem solving using these methods is business domain and/or subject matter expertise, which is not naturally possessed by most data scientists (but can be learned with time and experience). Organizations that are savvy to this nuance have taken to successfully teaming business experts with data scientists in the pursuit of results, but this model still finds difficulty scaling because it requires a great deal of expensive data scientists to properly activate the existing population of business analysts.
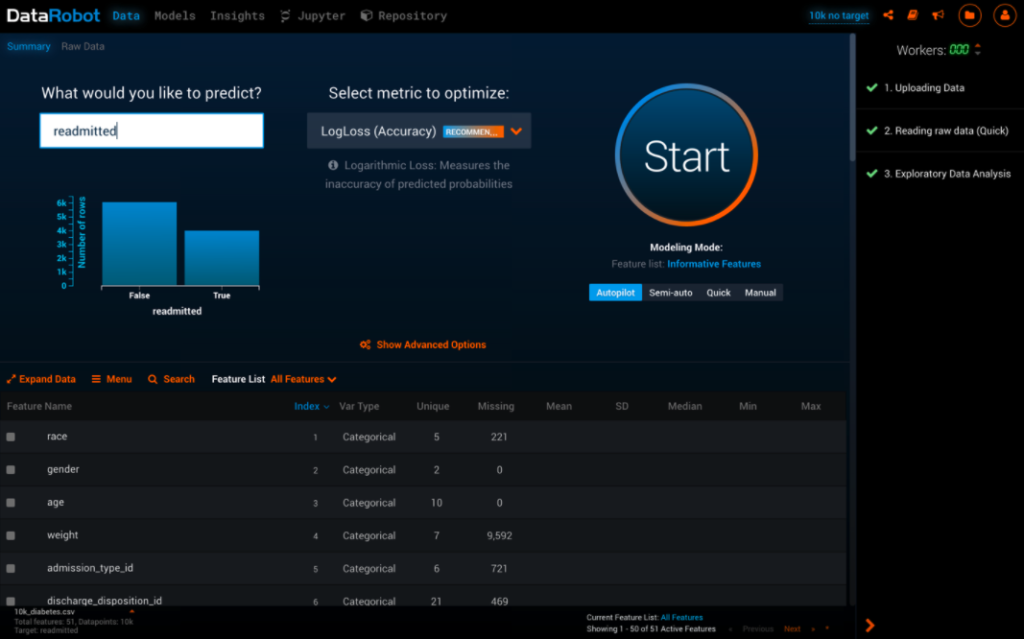
DataRobot’s category defining AML platform has an intuitive user interface that helps to train and up-skill business analysts on key machine learning concepts. The more you work with the platform, the more to learn about ML through means of guided apprenticeship.
Automated Machine Learning
Automated Machine Learning (AML) is an emerging class of data science toolkit that is finally making machine learning accessible to business subject matter experts. We anticipate that these innovations will mark a new era in data-driven decision support, where business analysts will be able to access and deploy machine learning on their own to analyze hundreds and thousands of dimensions simultaneously. Business analysts at highly competitive organizations will shift from using visualization tools as their only means of analysis, to using them in concert with AML. Data visualization tools will also be used more frequently to communicate model results, and to build task-oriented user interfaces that enable stakeholders to make both operational and strategic decisions based on output of scoring engines. They will also continue to be a more effective means for analysts to perform inverse analysis when one is seeking to identify where relationships in the data do not exist.
A great AML capability should benefit a business analyst or data scientist in the following ways:
- Data Preprocessing – Isolate training and validation data, discard sparsely populated features, impute missing or unknown values, perform text extraction and binning
- Feature Engineering – Transform and derive optimal features dates, numeric and categorical values depending on the algorithm in use
- Library of Algorithms – Draw upon a curated, contemporary and continuously updated library of machine learning algorithms to alleviate unrealistic expectations that your data science team will be able to perform ongoing R&D and integrate cutting edge methods on their own
- Algorithm Selection – Compare results of dozens or more algorithms and recommend the best ones for this modeling scenario
- Training and Tuning – Train models and tune parameters
- Transparency – Explain model design rationale, communicate feature importance both for the entire model and on a single prediction basis
- Deployment – Allow business users to deploy without IT intervention. Integrate models into business process for both online and offline systems, exportable code, REST Scoring APIs, batch predictions, integration with other enterprise systems and norms
- Management and Monitoring – Version control, monitoring and auditing, detection of model drift and inaccuracy over time
The Importance of Feature Engineering
There are limitations to the extent at which the machine learning process can be fully automated. While AML can perform time consuming and monotonous data pre-processing and feature engineering tasks, you will still need to engage the creativity and experience of your business domain experts to identify the best features (possible predictors) from the outset. You will also still need to have a strong understanding of your data systems, how your business processes work in practice, and how to correctly interpret the data that they generate. An interesting byproduct of AML and the democratization of machine learning is that more than ever businesses will compete on the strength of their data and the features they engineer. Even with the democratization of high-powered algorithms this key tenet of machine learning will continue to hold true; It will be the most meaningful features, not the most powerful algorithms, that will produce the best models.
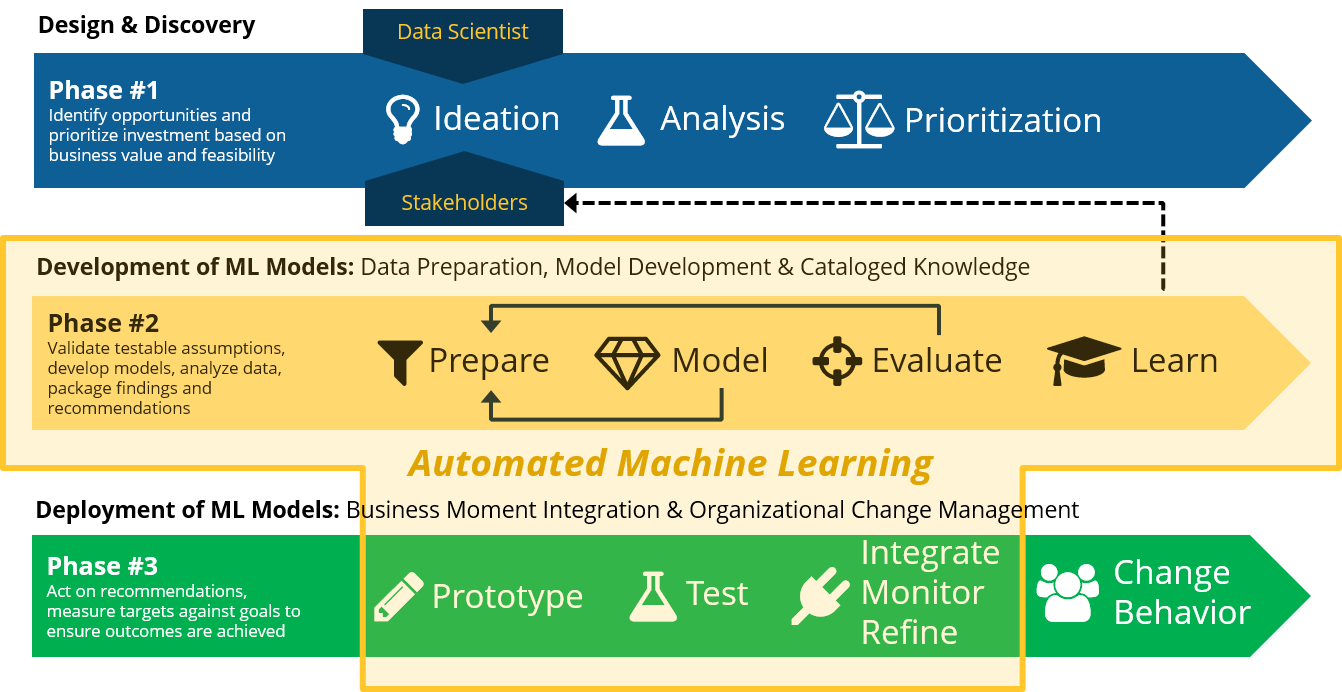
Automated Machine Learning can accelerate many parts of the data science and model development process but it is not a panacea. You still need to begin with a good hypothesis or business use case and an understanding of your problem domain.
Automated Machine Learning and The Data Scientist
The question we’re most often asked about AML is: Does this replace the need for having a data scientist? The answer is a resounding NO. You will still require someone with experience to provide guidance and check your work to prevent costly business errors. There are also certain types of machine learning problems that AML is not well positioned to solve. We strongly advise that your organization still rely upon experienced data scientists to serve as a highly leveraged shared service and a critical back-stop to provide oversight and advice to domain experts and analysts who are building models. The benefits of AML are best measured in terms of scale and speed. More analysts will be able to test more ideas quicker and arrive at more meaningful results than ever before. Businesses who are already doing data science will be able to do it better, faster and at lower costs, and those who are not yet doing data science will be able to quickly bootstrap their own practice by deploying AML to their analysts in concert with a single strategic data science hire, or by out-sourcing the back-stop role to a data science service provider.
Next Up: Master Data Management
Master Data Management is a comprehensive method of defining and managing critical data within an enterprise using a single point of reference. As decentralized data analysis becomes more prevalent, it is important to have a master data management capability incorporated into your organization’s plan to maximize the efficacy of your assets and knowledge.
About Ironside
Ironside was founded in 1999 as an enterprise data and analytics solution provider and system integrator. Our clients hire us to acquire, enrich and measure their data so they can make smarter, better decisions about their business. No matter your industry or specific business challenges, Ironside has the experience, perspective and agility to help transform your analytic environment.

