Five Essential Capabilities: The Data Catalog

This is part one in our five part series on the essential capabilities of the competitive data-driven enterprise.
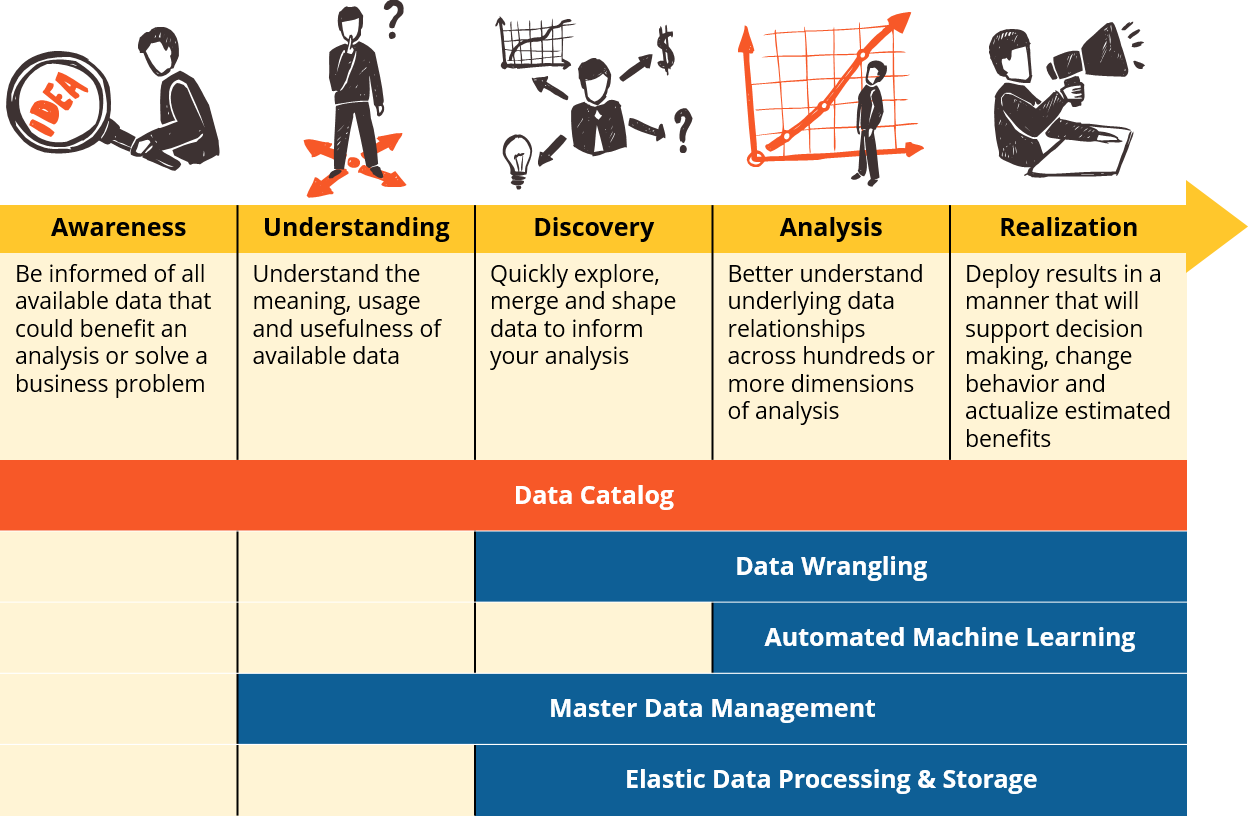
The most common form of data-enabled business problem solving begins with a hypothesis around business drivers and relationships within the data. Typically, a well tenured business analyst will pull together the data they know about or have access to in their department and proceed to build their analysis. This standard approach assumes that:
- The business analyst knows about and has access to all the data that might be relevant to the analysis.
- They understand the nomenclature of the data, its meaning and its usefulness. They know if there are flaws in the upstream business processes that might be causing the data to misrepresent what is happening in the real world, and they also know how to work with or around any of these biases and errors.
- They have the time in their day and the discipline to be diligent about documenting this tribal knowledge and imparting it upon others so that the organization can quickly and effectively onboard new analysts and scale out their ability to do data analysis.
Most veteran data analysts would agree that any combination of the above is rarely the status quo. Data analysts in one department or line of business often lack awareness of what other data could exist elsewhere in the enterprise that would improve their outcomes. What is worse, companies will often make large outlays for 3rd party data subscriptions and then will limit their ROI because of a lack of organization-wide knowledge that such powerful data assets are available for shared use.
Wikipedia for Your Business Data
To overcome these challenges, a powerful new capability has emerged in the form of a searchable catalog that functions as the organization’s Wikipedia or Google for enterprise data. The catalog should enable analysts to discover new data sources as well as understand and interpret them in the context of business analysis or data science. The most valuable data catalog solutions will offer powerful indexing and search and integrate with or catalyze the organization’s data governance program.
State and local governments have been rapidly adopting feature-rich data catalogs like Socrata and CKAN to promote open government and provision public-domain datasets. Why shouldn’t your business make similar strides to catalyze corporate data innovation?
Following lean principles of product management, the office of the Chief Data Officer or the centralized data management function will rely heavily on the data catalog usage statistics to assign value to data assets and prioritize what information needs to be governed, mastered or integrated to increase data efficacy. In addition, you can use the data catalog as a low cost way of surfacing new data to consumers without first having to move it from an operational system into a warehouse or lake – simply add the source to the catalog and allow it to be crawled and indexed.
Next Up: Data Wrangling
Once an analyst or data scientist becomes aware and has developed a data understanding, the next step in the process is to blend and shape that data to support their analysis. In days of old, most analysts had one of a few options: plead with their highly specialized and often over-burdened ETL and data warehouse development team to model the data for them, or use SQL and Excel (or more likely some combination of all three). A new powerful class of data manipulation tools are enabling analysts to independently model data with fewer specialized skills and businesses are spending less on development and building new decision support applications faster and more frequently than ever.
About Ironside
Ironside was founded in 1999 as an enterprise data and analytics solution provider and system integrator. Our clients hire us to acquire, enrich and measure their data so they can make smarter, better decisions about their business. No matter your industry or specific business challenges, Ironside has the experience, perspective and agility to help transform your analytic environment.

