IBM Cognos CSV Files: The Encoding Mystery
Editor’s Note: This blog was originally posted on April 14, 2011, and has been reviewed on October 5, 2020 to reflect Cognos analytics changes. Exporting Cognos report data in CSV is one of the most frequently used output formats, and it is very common to leverage those CSV files in other applications and tools. For example, for data integration or as data feed in other system. Thus we find that knowing how to address text encoding issue is still a very helpful topic, specifically when transfer CSV file between different operation systems, which default character set and encoding maybe different. Many populate text editor like Notepadd++, Textpad can switch encoding easily, an alternative method to convert encoding of CSV file outside Cognos. Let’s know what are the solutions or challenges in your unique scenarios.
The ability to export a report to CSV format is one of great out of box capabilities provided by the IBM Cognos suite of tools. A delimited text (CSV) file can be opened in any application associated with the .csv file type, such as Microsoft Excel, Microsoft Wordpad, or Star Office in Unix. In addition, the CSV format file is also widely accepted by most modern database vendors. Providing the end users with this ability makes report data easily re-usable and integration friendly with other applications.
Of course, there are always caveats to consider with any technology solution. For example, I once had a project where the customer informed me that the exported CSV data file couldn’t be used in a third party application. The numeric information and English letters appeared as unreadable “symbols” when the file was consumed by their particular application. Since a CSV file should have no issues being consumed by any application, why was it that this plain CSV file couldn’t be interpreted by that application? After research and some testing, I was able to quickly identify that the root cause was “surprisingly” simple – the character encoding.
To uncover the mystery, let’s first take a look at what can be found inside the “plain-looking” CSV formatted text file. By default Cognos reports saved in CSV format utilize the following attributes:
- Designed to support Unicode data across many client operating systems.
- UTF-16 Little Endian data-encoded.
- Include a BOM (Byte Order Mark) at the beginning of the file.
- Tab-delimited.
- Does not enclose strings in quotation marks.
- Uses a new line character to delimit rows.
- Show only the results of a report query. Page layout items, such as titles, images, and paramDisplay values do not appear in the CSV output.
More details can be found at: https://www.ibm.com/support/knowledgecenter/SSEP7J_11.1.0/com.ibm.swg.ba.cognos.ug_cr_rptstd.doc/c_cr_rptstd_intrd_csv_format.html
As you can see, the CSV file is no longer “plain-looking” but includes multiple different characteristics which must be considered in various cases.
For our example, we will focus on the fact that in the CSV formatted report characters are encoded in UTF-16/Unicode, which is widely used today in many applications (but not all!) to support multi-language. Why characters need to be encoded? Fundamentally computers just deals with numbers. It stores letters, numbers and other characters by assigning a numeric value for each one. Before Unicode was invented, there were many different character encoding systems for assigning these numbers to represent characters. This leads to a significant problem as no single encoding method could contain enough characters to represent even just one single language. For instance, in the English language no single encoding is adequate for all the letters, punctuation, and technical symbols commonly used.
Unicode became the solution. It provides a unique number for every character, no matter what the platform, no matter what application, no matter what the language. The Unicode Standard has been adopted by most industry leading leaders. It is supported in many operating systems, all modern browsers, and many other applications/systems. Unicode enables a single software product such as a single website to be targeted across multiple platforms, languages (countries) without re-engineering. It allows data such as a Cognos report CSV formatted data file to be transferred through many different systems without corruption. That being said, as long as the target system supports Unicode then there should be no issues with re-using the Cognos exported CSV data. In the scenario I have mentioned above, as you can imagine the issue is caused by the target system, which didn’t support Unicode.
I am sure the next question you will ask is how to resolve such encoding conflicting issue? Is there a way to set encoding method when exporting a Cognos report in CSV formatted? Fortunately the answer is “Yes”. You can modify properties for the exporting CSV output format from Cognos system admin console.
Here are the Steps:
- Log in as system administrator, click on “Manage”
- Select the “Administration Console” from the menu
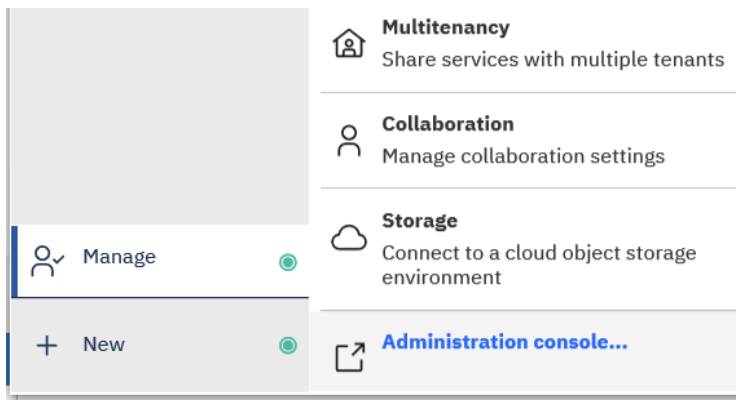
3. On the Status tab, click System.
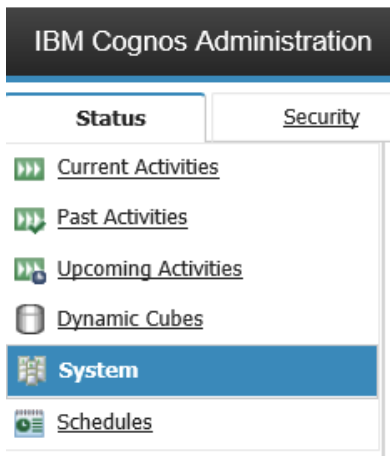
4. From the System drop-down menu, click Set properties.
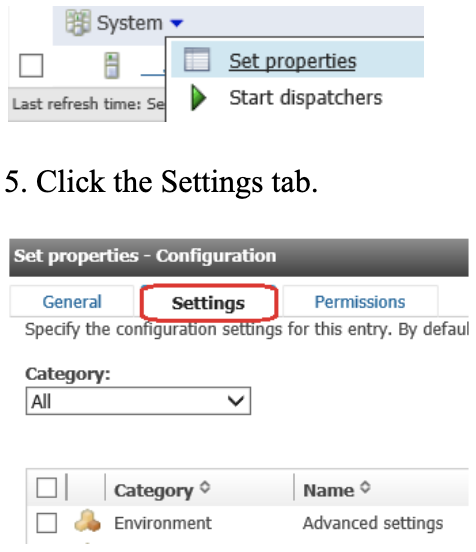
6. Next to Environment, Advanced Settings, click Edit.

7. Enter parameter RSVP.CSV.ENCODING and a supported encoding value such as windows-1252 which is also known as “Windows characters”. The default value Cognos used is utf-16le.

8. Click OK. Wait about 30 seconds to take changes effect.