An Introduction to Master Data Management

Is your company suffering from a case of “Bad Data”? Everyone is following the process and doing their job correctly but you still face issues with accurate reporting, operational errors, audit anxiety about your data, etc. Good data should be a given, right?
Well it’s not that easy. In today’s business environment, rapid growth, organizational change, and mergers and acquisitions (M&A) are very difficult to absorb within a fragmented data ecosystem. Multiple disparate IT systems, siloed databases, and deficient master data often result in data which is fragmented, duplicated and out of date.
This situation is often a symptom of poor or no Master Data Management (MDM), which provides a clean, trusted, single view of some of the most important data in your company, like your customers, products, and suppliers. MDM links them all together to create that single mastered view and can share this data with all of your business partners so you’re on the same page internally and with your customers.
MDM is considered a cornerstone to a good data governance program and the health of your data ecosystem. Let’s take a look at what MDM is and how an MDM program is implemented within an organization.
What is Master Data?
Master data is the entities, relationships, and attributes that are critical for an enterprise and foundational to key business processes and application systems. It’s not all the data about a subject area, (Data Domain), but it’s the pieces (Data Entities) you care about. These pieces are like the data elements on a web form with the asterisk (*) next to them, the mandatory ones.

Master data can also be the items on the drop down lists these systems provide to make choices (Reference Data). Some examples of reference data would be ISO Country Codes, transaction types, and industry categories. In some cases, master data can include operational type data to make things run better, like customer preferences to improve your customer’s experience.
Master data also includes the linkages (relationships) between your business entities to give you an integrated view of your data. These relationships are especially valuable when reporting and creating analytics within and across data domains. These relationships are critical to the slicing and dicing of data.
Within any company, it is common to want to view your customers by product line, geography or sales region. These hierarchies can be part of your master data.
Often, externally supplied data is also linked within master data, providing rich extensions to your internal data. Numerous data sets are available today to expand your data validation, and provide a broader view of your entities. Address validation, Geospatial data, Risk by Geo data, and Global Legal Entity data are a few of the many data sets available.
Master data does not include the transactions that happen in the course of doing business. I’ve seen master data described as “the Nouns of the data but not the Verbs.” The verbs or action words would be the transactional data.
Deciding on what the Master Data is within your company requires collaboration with all of your internal business partners to get it right, as well as IT.
What is Master Data Management?
Master Data Management (MDM) is the organization of people, processes and technologies to create and maintain an authoritative, reliable, sustainable, accurate, and secure data environment that represents a “single version of the truth” for master data and its relationships across the enterprise.
Let’s break that definition down a little further:
The People Involved
-
- MDM Program Executive Sponsor – provides organization and resource support; able to help articulate the importance of MDM in your organization. They would be the champion of change to help communicate the benefits, the work to be done and how change fits into corporate goals. They are a vital component of a successful Data Governance and Master Data Program.
- Business Owners – These folks are considered the real owners of master data in an organization because they are the ones who know the data the best and the ones who are directly impacted by the consequences of bad data and the rewards of good data. Each business unit who shares a dependency on the data being considered for mastering should be represented in the MDM program. These are the people who will help define, prioritize and measure the success.
- Data Stewards – The data stewards take ownership of the day-to-day maintenance and data governance. They insure the data meets the quality standards put in place and takes corrective action on exceptions.
- System Owners – These are the people knowledgeable about specific business applications and systems within the data ecosystem. They provide system SME and access data timing and the processes which operate within a particular business application. The system owners provide access and technical knowledge to the team.
- MDM SME – These are the navigators of implementing the MDM program. They bring the knowledge and experience to help plan and execute an MDM program. They help define and implement the solutions based on the specific needs of the company.
All of these people should be a part of the Master Data Management team and can be considered the steering committee for putting MDM in place and managing the MDM program moving forward.
The Processes
There are 2 process areas to consider when looking at Master Data Management.
-
- The business process that will be affected when implementing a MDM program. These changes are identified during the planning of an MDM initiative and described as a component of a Use Case. Multiple changes can happen to business processes as the MDM program matures.
- The governance processes put in place to maintain the master data program, the health of the data, and the monitoring, error handling and change of data after MDM is put in place.
The Technology
There are several excellent platforms in the market today that provide the tools to help you implement a master data management program. Whether they come as a suite or are selected individually, the functions they perform are similar to make up your MDM platform. At the core of your operational MDM platform is a data store, which houses the cleansed “single source of the truth.”
At the front end of your MDM platform is the extraction component which moves all of your source data into the MDM platform as a one time load. After this, your data will typically be incrementally loaded as change occurs. This is usually called the Extract, Transform and Load (ETL) component.
Within the MDM platform, the source data goes through a series of cleansing steps in order to become available as the “single source of truth.” When this is done, you’re ready to share your mastered data with applications, data warehouse, business intelligence and customer interactions with a common view of cleansed, de-duplicated data.

Wow, that was easy. Well, not so fast. There are a few missing details.
In order to cleanse the data and make it ready, components within the MDM platform will need to be set up. This requires configuration of rules engines, validation against reference data, and possibly external validation or custom coding for unique situations.
These steps require analysis, design and development to create the cleansing path the data will take (workflow). A good first step in the analysis is source data profiling. There are good tools out there (data profilers) to help you analyze and diagnose the quality of your data regarding the accuracy, completeness and integrity.
This understanding can then be used to help define and automate the rules to put in place to build your cleansing workflow:

Standardization – Standardization involves aligning data from different sources into a common structure, format and definition, such as customer name coming from two different systems which allow different lengths, case and spelling. Another example would be dates that use different formats like January 1, 2022, 01/01/22, 01-Jan-22. This standardization process gives you your best shot at comparing “Apples to Apples.” Standardization can also include the validation of this data against an external data source. For example, the validation of addresses against an authoritative address database to insure accuracy and will often fill in the blanks for missing data.
Matching – Once your data is in a comparable state, matching can take place. Matching is the identification of duplicate data based on a set of matching criteria. You may want all the records with company name, address and phone numbers that are the same to be considered the same record (a match).
Merging – Once duplicates are identified, they can be merged into that “Single Source of the Truth.” Duplicates may have varying degrees of quality and the winner of quality would be the survivor. On the first run of this process, the initial load, this survivor is designated as “Best of Breed.”
Best of Breed – On subsequent incremental processing of additional data, the current Best of Breed record will be challenged and replaced if a better record comes along.
Launching an MDM Program
Now that we have a sense of what Master Data and Master Data Management is, you may ask, “How would you implement a Master Data Management Program?”
Although MDM is much like other software development initiatives in many ways, it does have its peculiarities. MDM needs to be driven by the business leaders in collaboration with Information Technology. Too often, MDM is attempted by IT alone and can lead to de-prioritization and failures because IT are not the ones with the most pain with bad data and subsequent gain that MDM offers.
An MDM implementation should start with a healthy planning phase where your steering committee is assembled, your executive sponsor is identified, the use cases you want to conquer are defined, the return on investment is developed, and a roadmap is established to guide the development based on priorities of the organization.
I highly recommend appointing a navigator on the team who has traveled these waters before and can help avoid the rocks. They will be especially helpful in use case development, vendor selection and aligning the roadmap effectively.
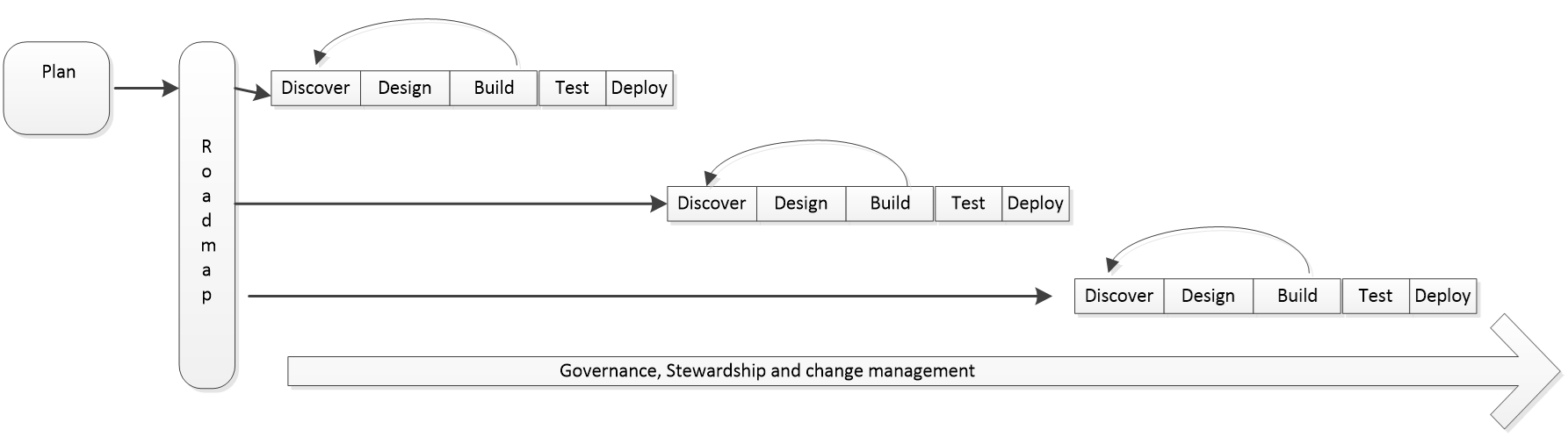
Once the planning is in place, the development should follow a pattern for fulfilling the roadmap. Each use case or common set of use cases follow a standard lifecycle to deliver incremental benefit.
The Discovery phase is the time to do the data analysis and profiling to understand the source data and its condition. This is also the time to refine the use cases into functional requirements to prepare for the Design and Build of the solution. Notice the arrow in the diagram pointing back from Build to Discovery. This alludes to the iterative process typically followed in the development of an MDM solution. Much like peeling an onion, data nuances will be discovered and addressed as you move further through the phases.
This is why an Agile style project works well with MDM. It lets you move through and adjust to get the most benefit from your efforts.
Whether you implement Master Data Management on a sophisticated Graph Database or on the back of a napkin (I don’t recommend the napkin approach), you should realize that MDM is an ongoing process, not a single project. By its nature, MDM must evolve with the changes in your business. Keep this in mind as you move through the initiation of MDM, and your program will yield ever increasing value to your organization.

About Ironside
Ironside was founded in 1999 as an enterprise data and analytics solution provider and system integrator. Our clients hire us to acquire, enrich and measure their data so they can make smarter, better decisions about their business. No matter your industry or specific business challenges, Ironside has the experience, perspective and agility to help transform your analytic environment.

